题目描述
输入一段英文文本,统计其中每个单词出现的次数。
要求:
(1)去除文本中的无意义词及标点符号。
无意义词:excludes = {‘the ’,’and’,’to’,’of’,’a’,’be’}
(2)按词频从大到小的顺序输出前10 个单词及词频。
案例代码
import re
from collections import Counter
# 输入英文文本
text = input("请输入英文文本: ")
# 去除标点符号并转换为小写
text = re.sub(r'[^\w\s]', '', text).lower()
# 分割成单词列表
words = text.split()
# 去除无意义词
excludes = {'the', 'and', 'to', 'of', 'a', 'be'}
filtered_words = [word for word in words if word not in excludes]
# 统计单词出现次数
word_counts = Counter(filtered_words)
# 按词频从大到小排序
sorted_word_counts = dict(sorted(word_counts.items(), key=lambda item: item[1], reverse=True))
# 输出前10个单词及词频
top_10_words = list(sorted_word_counts.items())[:10]
for word, count in top_10_words:
print(f"{word}: {count}")这段Python程序首先接收用户输入的英文文本,然后去除标点符号并转换为小写,接着将文本分割成单词列表。然后去除无意义词,并利用Counter类统计单词出现次数,最后按词频从大到小排序并输出前10个单词及词频。
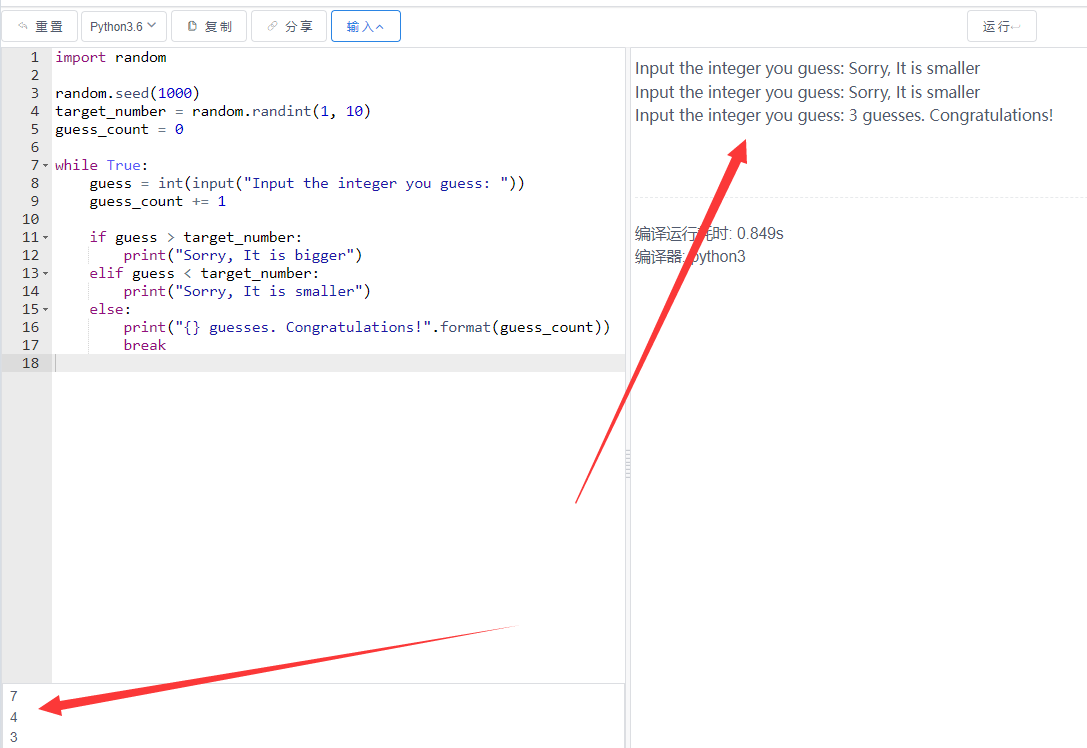
运行截图
![图片[1]-输入一段英文文本,统计其中每个单词出现的次数-QQ沐编程](https://www.qqmu.com/wp-content/uploads/2023/11/pycount.png)
© 版权声明
本站资源来自互联网收集,仅供用于学习和交流,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!
THE END