源码介绍
以下是一个简单的Python爬虫项目案例代码,用于通过网页爬虫抓取英雄联盟(League of Legends)游戏中的人物头像图片。在这个案例中,我将使用requests库和BeautifulSoup库来实现网页数据的获取和解析,完整代码在文章底部,感兴趣的朋友可以拿去使用或者进行学习研究。
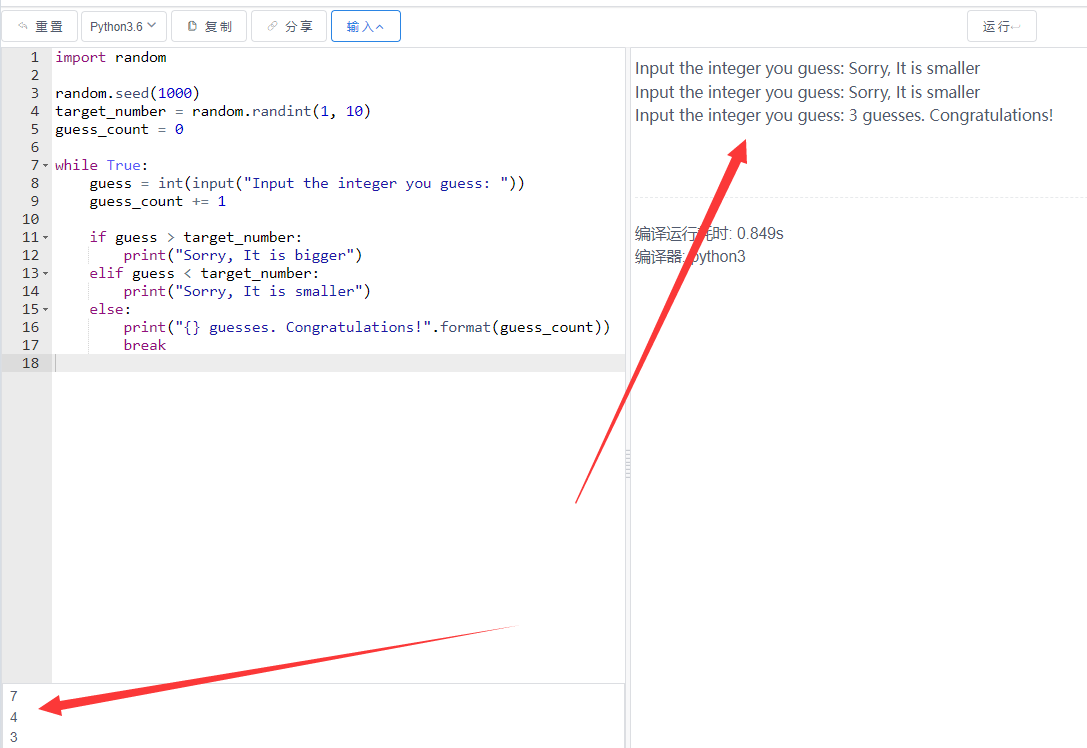
效果如下
![图片[1]-Python爬虫项目之爬取LOL英雄联盟英雄头像案例代码-QQ沐编程](https://www.qqmu.com/wp-content/uploads/2024/03/python_lol.jpg)
项目代码
import requests
import os
# API获取英雄列表信息
url = 'https://ddragon.leagueoflegends.com/cdn/13.6.1/data/en_US/champion.json'
response = requests.get(url)
if response.status_code == 200:
champions_data = response.json()['data']
# 创建保存图片的文件夹
if not os.path.exists('lol_champions'):
os.makedirs('lol_champions')
for champion in champions_data.values():
champion_name = champion['id']
image_url = f"https://ddragon.leagueoflegends.com/cdn/13.6.1/img/champion/{champion['image']['full']}"
# 下载图片并保存到文件夹中
with open(f'lol_champions/{champion_name}.jpg', 'wb') as f:
img_data = requests.get(image_url).content
f.write(img_data)
print("图片下载完成!")
else:
print("请求失败")这段代码通过League of Legends官方API获取英雄数据,并从中提取每个英雄的名称和对应的图片链接,然后将图片下载到名为”lol_champions”的文件夹中。请确保你的网络连接正常,并且你有权限使用League of Legends的API。
© 版权声明
本站资源来自互联网收集,仅供用于学习和交流,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!
THE END