麻雀搜索算法(Sparrow Search Algorithm,简称SSA)是一种新兴的多元函数优化算法,其思想源于麻雀在寻找食物时的行为。下面介绍如何编写麻雀搜索算法的代码。
首先,需要定义一个适应度函数,用于评估每个解的优劣程度。适应度函数的具体形式取决于所要求解的问题,可以根据问题的特点进行设计。
然后,需要初始化一群麻雀,这些麻雀代表了搜索空间中的不同解。可以使用随机数生成初始解,也可以采用其他方法。
接下来,需要根据麻雀的行为规律,对麻雀进行搜索和更新。麻雀搜索算法的主要思想是通过麻雀之间的竞争和合作来实现搜索过程。具体地,每只麻雀会计算自己的适应度值,并与周围的麻雀进行相互协作或竞争,以找到更优的解。具体操作如下:
- 计算每只麻雀的适应度值。
- 根据适应度值对麻雀进行排序,选出最优秀的一部分麻雀。
- 对于每只麻雀,随机选择一些周围的麻雀,并与它们进行竞争。竞争的结果可能是胜利、失败或平局。
- 对于胜利的麻雀,更新其位置和适应度值。对于失败的麻雀,根据一定的概率更新其位置和适应度值。对于平局的麻雀,也可以根据一定的概率更新其位置和适应度值。
- 重复步骤1-4,直到满足停止条件。
最后,需要定义停止条件,例如达到最大迭代次数或满足一定的精度要求等。
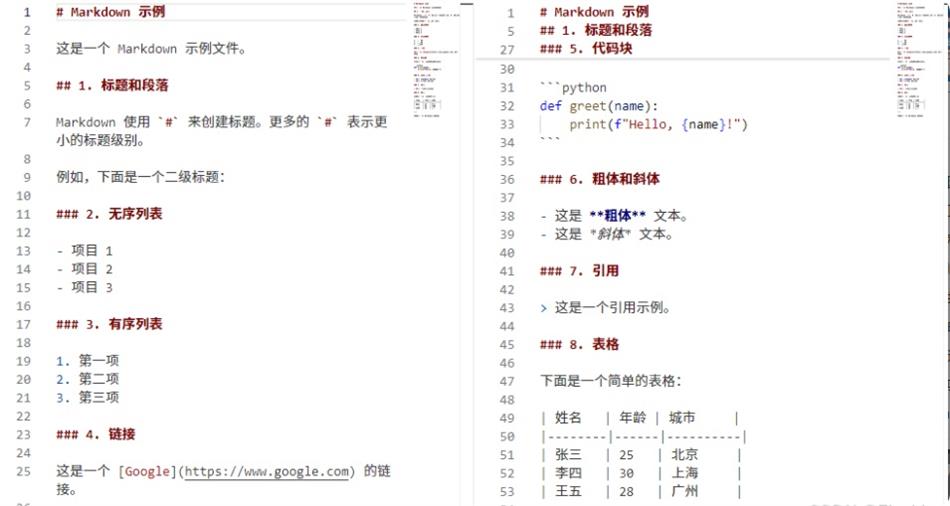
下面是一个简单的麻雀搜索算法的代码实现,其中假设要求解的问题是一个二元函数的最小值:
import random
# 定义适应度函数
def fitness(x, y):
return (x - 2) ** 2 + (y + 3) ** 2
# 初始化麻雀群体
n = 20 # 麻雀数量
xmin, xmax = -10, 10 # x的取值范围
ymin, ymax = -10, 10 # y的取值范围
sparrows = [(random.uniform(xmin, xmax), random.uniform(ymin, ymax)) for i in range(n)]
# 迭代搜索
max_iter = 100 # 最大迭代次数
for i in range(max_iter):
# 计算每只麻雀的适应度值
fitnesses = [fitness(x, y) for x, y in sparrows]
# 根据适应度值对麻雀进行排序,选出最优秀的一部分麻雀
sorted_sparrows = [sparrows[i] for i in sorted(range(n), key=lambda k: fitnesses[k])]
# 对于每只麻雀,随机选择一些周围的麻雀,并与它们进行竞争
for j in range(n):
opponents = random.sample(sorted_sparrows[:j] + sorted_sparrows[j+1:], 3)
winner = sparrows[j]
for opponent in opponents:
if fitness(*opponent) < fitness(*winner):
winner = opponent
# 更新胜利的麻雀
if winner != sparrows[j]:
sparrows[j] = winner
# 判断是否满足停止条件
if i % 10 == 0:
best = sorted(sparrows, key=lambda x: fitness(*x))[0]
print(f"Iteration {i}: Best solution ({best[0]:.2f}, {best[1]:.2f}), fitness = {fitness(*best):.2f}")这个例子中,我们假设要求解一个二元函数 的最小值。首先定义适应度函数 fitness,然后使用随机数初始化20只麻雀的位置。接下来,进行100次迭代搜索,每次迭代中计算每只麻雀的适应度值,并根据适应度值对麻雀进行排序。然后对于每只麻雀,随机选择3只周围的麻雀进行竞争,并更新胜利的麻雀。最后输出每10次迭代中最优解的位置和适应度值。
需要注意的是,麻雀搜索算法的性能受到很多因素的影响,例如参数设置、搜索空间的维度和复杂度等。因此,在实际应用中需要针对具体问题进行调整和优化。
© 版权声明
本站资源来自互联网收集,仅供用于学习和交流,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!
THE END