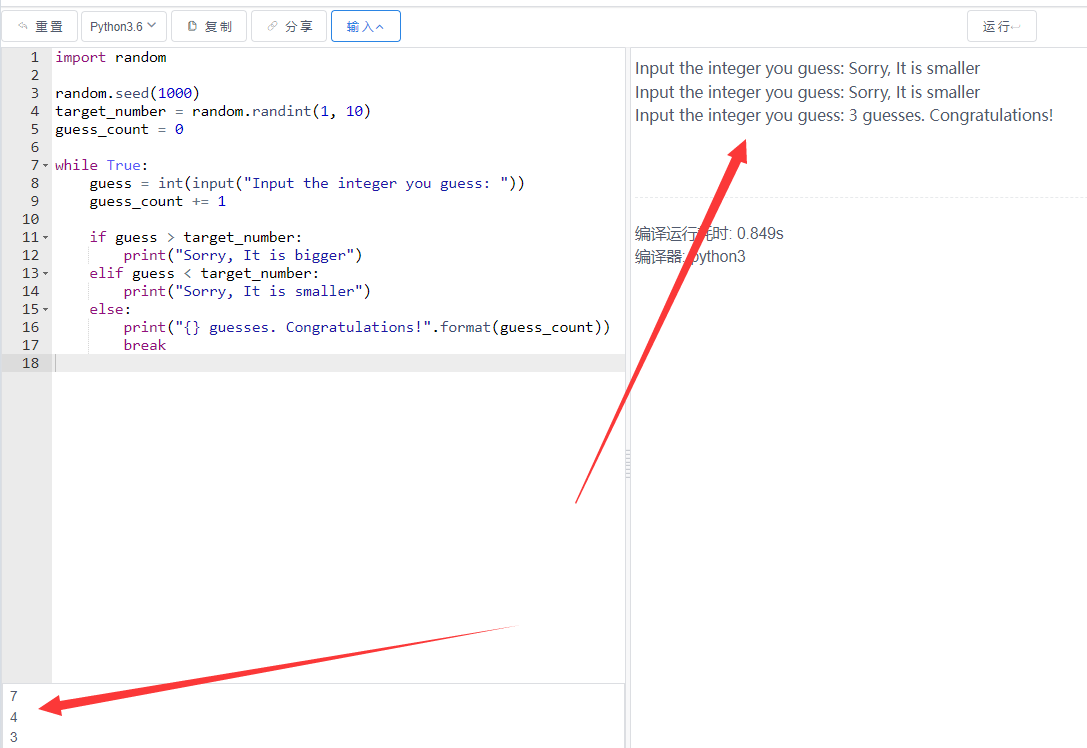
题目描述
现在你有天龙八部的文件TLBB.txt和出现的所有角色名文件npc,完成下列功能:
- 统计出场次数最高的10大角色.
- 统计一共多少章、每章平均多少个汉字、汉字数最多是哪一章、汉字数最少是哪一章
- 请统计角包与角色之间关系紧密度最高的十对组合。所谓关系紧密程度是由在同一章中两个角包都同时出现过
实现代码
要完成这个案例,你可以使用Python来读取和处理文本文件。以下是一个示例代码,用于解决你提出的问题:
import re
from collections import Counter
# 统计出场次数最高的10大角色
def get_top_characters(file_path, npc_file_path):
# 读取TLBB.txt文件内容
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
# 读取npc文件中的角色名
with open(npc_file_path, 'r', encoding='utf-8') as f:
npc_names = f.readlines()
npc_names = [name.strip() for name in npc_names]
# 使用正则表达式匹配角色名并统计出现次数
character_counts = Counter(re.findall(r'\b(?:%s)\b' % '|'.join(npc_names), text))
# 获取出场次数最高的10个角色
top_characters = character_counts.most_common(10)
return top_characters
# 统计章节数、平均每章汉字数、汉字数最多和最少的章节
def get_chapter_statistics(file_path):
# 读取TLBB.txt文件内容
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
# 使用正则表达式分割文本为章节
chapters = re.split(r'\n第.+章', text)[1:]
chapter_count = len(chapters) # 章节数
total_characters = sum(len(chapter) for chapter in chapters) # 总汉字数
average_characters = total_characters / chapter_count # 平均每章汉字数
# 获取汉字数最多和最少的章节
max_characters_chapter = max(chapters, key=len)
min_characters_chapter = min(chapters, key=len)
return chapter_count, average_characters, max_characters_chapter, min_characters_chapter
# 统计角色之间关系紧密度最高的十对组合
def get_top_relationships(file_path, npc_file_path):
# 读取TLBB.txt文件内容
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
# 读取npc文件中的角色名
with open(npc_file_path, 'r', encoding='utf-8') as f:
npc_names = f.readlines()
npc_names = [name.strip() for name in npc_names]
# 使用正则表达式匹配角色名在同一章中的出现情况
pattern = r'^(?=.*(?:%s)).*$' % '|'.join(npc_names) # 至少同时包含两个角色名的正则表达式
matches = re.findall(pattern, text, flags=re.MULTILINE)
# 统计角色之间的关系紧密度
relationship_counts = Counter()
for match in matches:
characters = re.findall(r'\b(?:%s)\b' % '|'.join(npc_names), match)
combinations = [(x, y) for idx, x in enumerate(characters) for y in characters[idx + 1:]]
relationship_counts.update(combinations)
# 获取关系紧密度最高的十对组合
top_relationships = relationship_counts.most_common(10)
return top_relationships
# 主程序入口
if __name__ == '__main__':
file_path = 'TLBB.txt'
npc_file_path = 'npc.txt'
# 统计出场次数最高的10大角色
top_characters = get_top_characters(file_path, npc_file_path)
print("出场次数最高的10大角色:")
for character, count in top_characters:
print(f"{character}: {count}次")
print()
# 统计章节数、平均每章汉字数、汉字数最多和最少的章节
chapter_count, average_characters, max_characters_chapter, min_characters_chapter = get_chapter_statistics(file_path)
print("章节数:", chapter_count)
print("平均每章汉字数:", average_characters)
print("汉字数最多的章节:", max_characters_chapter[:20]) # 只打印部分章节内容
print("汉字数最少的章节:", min_characters_chapter[:20]) # 只打印部分章节内容
print()
# 统计角色之间关系紧密度最高的十对组合
top_relationships = get_top_relationships(file_path, npc_file_path)
print("角色之间关系紧密度最高的十对组合:")
for (character1, character2), count in top_relationships:
print(f"{character1} - {character2}: {count}次")在这个程序中,我们首先读取TLBB.txt和npc.txt文件的内容。然后使用正则表达式进行匹配和统计。通过Counter类可以方便地获得出现次数最多的角色、关系紧密度最高的角色对等信息。
请确保将TLBB.txt和npc.txt文件放置在与程序相同的目录下,并根据实际情况修改文件路径。
此外,为了更好地处理文本数据,你可能需要了解更多关于字符串处理、正则表达式和文件操作方面的知识。
© 版权声明
本站资源来自互联网收集,仅供用于学习和交流,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!
THE END